
You probably arrived here because you are also interested in extracting the vocabulary for a specific language from Duolingo and use the vocabulary for further purposes. In this case I used it to import it into Quizlet.
| github.com/melledijkstra/duolingo-vocab-extractor |
The reason why I do this is that I have the idea that Quizlet is a bit better in spaced repetition than Duolingo at the moment. Also I like to have different ways of learning a language. So, at this moment I wanted to extract the Swahili vocabulary from Duolingo.
There are simple extensions in Chrome you can utilize to extract data from a webpage easily. While that works, I also wanted to have the translations of the different terms and the sentence examples that Duolingo provides. That was a bit harder because I needed to extract the data from different places. Also, I know that it’s quite easy to extract the vocabulary of the user, but the complete vocabulary of the language is a bit harder to get. Also, I haven’t found an overview that shows the definitions.
My first approach was to use the scrapy python package to extract the data, but this quickly seemed to be a bit overkill.
So first things first, I created a python virtual environment to do all my testing. The first task is to get all the vocabulary words (terms). There are different places to retrieve the term list in different ways. For example https://duome.eu/MelleDijkstra/progress has a lot of information that is not displayed on the official website of Duolingo. It won’t be too hard to extract it from there.
In my case, I chose to extract the terms from the skills tab. From this tab I should be able to extract all the terms grouped by the exercise they are linked with. With some simple javascript I got the following result:
dictionary = {}
$('li.shift').each(function(i, elem) {
let exercise = $(elem).find('span.sTI').text();
wordbox = $(elem).find('.blue').clone();
wordbox.find('small').remove();
let terms = wordbox.text().split(' · ');
dictionary[exercise] = terms;
});
JSON.stringify(dictionary);
{
"Introduction":
["emilian","jina","juma","la","lake","lako","langu","mchina","mholanzi","mimi","mkenya","mmarekani","mtanzania","nani","ni","ninyi","rehema","sisi","wachina","waholanzi","wakenya","wamarekani","wao","watanzania","wewe","yeye"],
"Greetings 1":
["asubuhi","baba","babu","bibi","dada","habari","hajambo","hamjambo","hatujambo", ...
...
}
And it gives perfectly all the vocabulary needed to get the translations. I downloaded the Swahili JSON to a file to continue in python.
Note: you can click on the tab headings first before running the script to get the specific order you prefer.
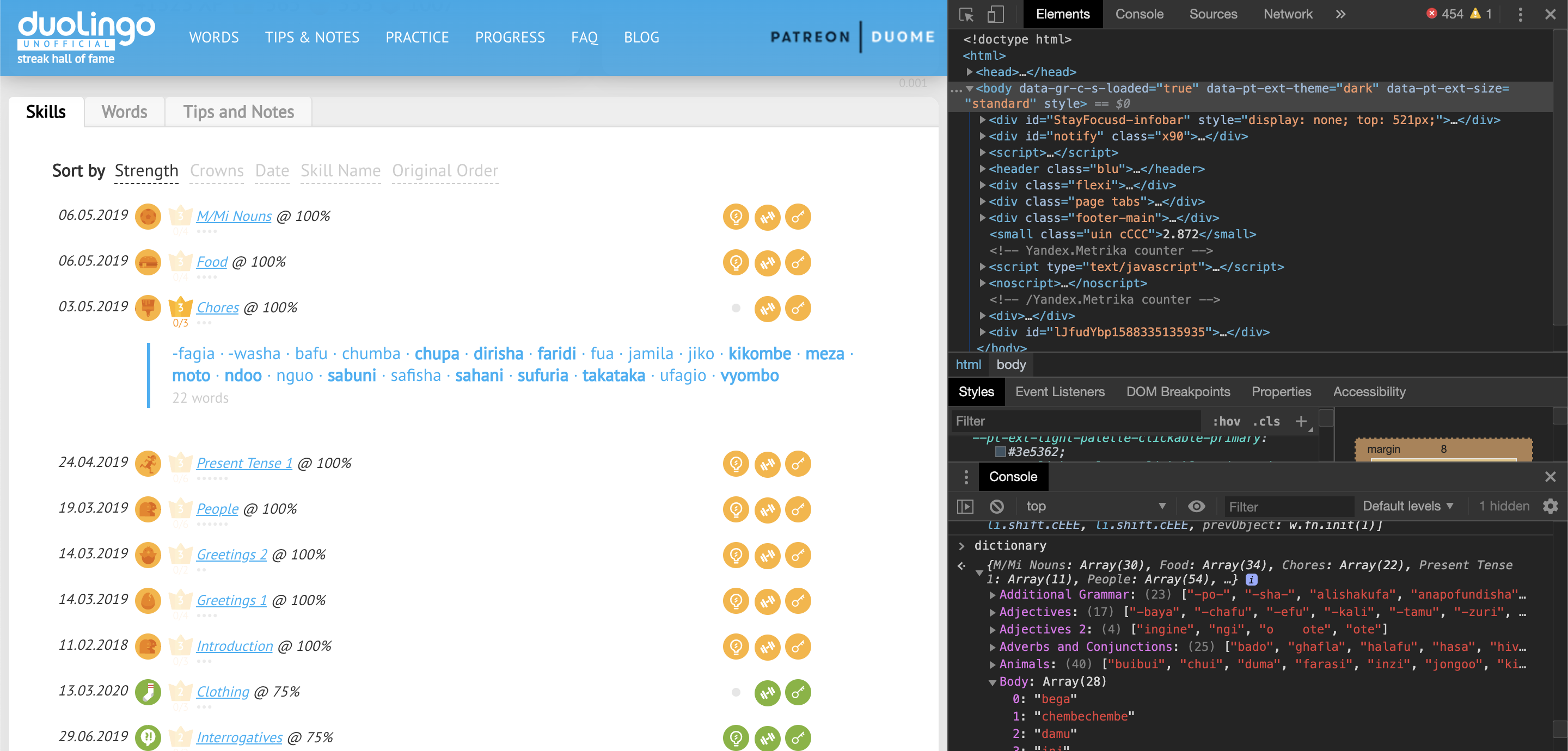
Nice! One step done. Now that I have all the words in the vocabulary for a particular language, I can start retrieving the translations and the example sentences that Duolingo provides. These are the same example sentences and words that you get during the exercises in the mobile application and on the web version.
I needed to know the entry point of where we can find the translations. Duolingo has a dictionary for most languages, this is a good starting point. I went to https://www.duolingo.com/dictionary/Swahili/baba and used the word ‘baba’ as an example. I first created a python script that makes a request to this dictionary and wanted to extract the translation info from the HTML. Unfortunately that didn’t go as expected. The page loads dynamically with some javascript code and with python requests this javascript does not load. Instead, I searched for the source where the javascript in turn loads the translation data.
From the developer tools in the network tab it’s visible where the data comes from. Easy as that, it seems that there is an unofficial API that the javascript uses to retrieve the data. With python this API is even easier to work with because it returns JSON as the response format.
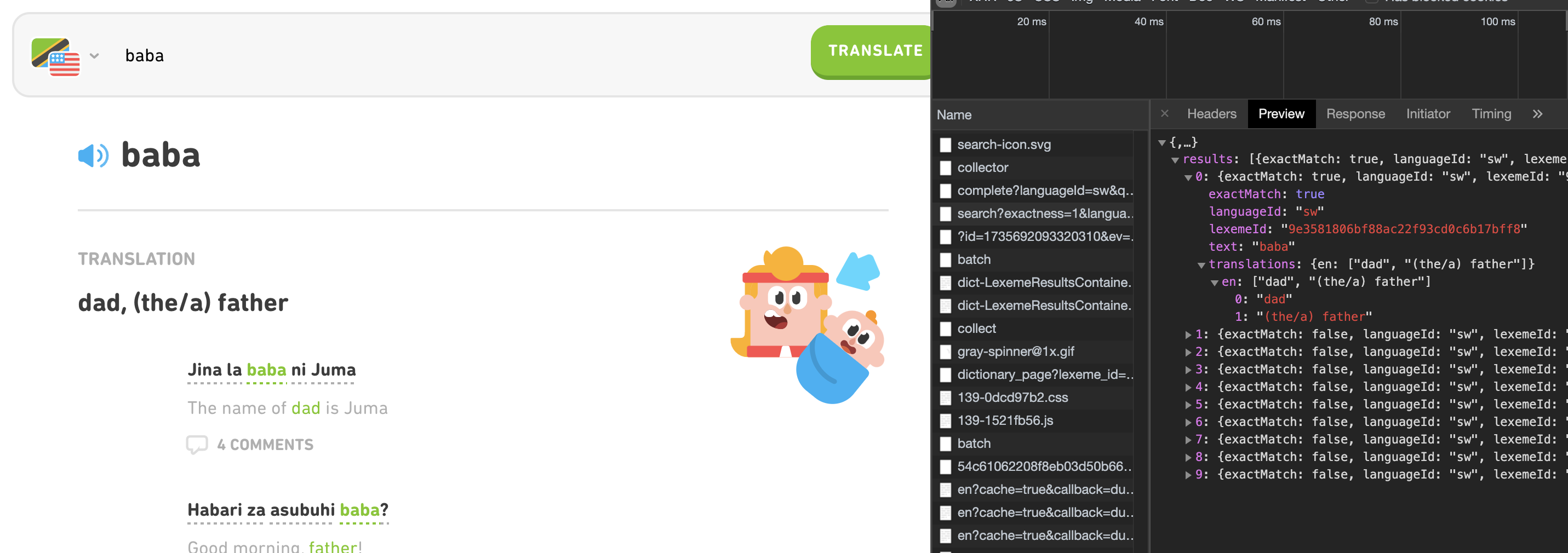
Actually there are two different endpoints (APIs) from where this data on the webpage is retrieved. One is for the dictionary which tries to match the search input to a term or word that is known in the Duolingo database. If there is a match it provides a list of possible matches with their lexeme_id . This lexeme_id is important for the second endpoint to retrieve the information for this particular lexeme. The information from the second API are very helpful. It contains the example phrases, translations, text-to-speech audio (url) and more info about the lexeme.
With this information I knew where and which data to retrieve. I created the python script below which does all the necessary work and stores the information in a JSON file. This JSON file is now ready to do any further steps you want to take with the data. For me, I want to import the data into Quizlet.
import requests as req
import json
def get_lexem_data(lexem_id=None, from_language_id='en'):
def __get_phrases(alternative_forms):
phrases = []
for form in alternative_forms:
phrases.append({
'text': form['text'],
'tts': form['tts'],
'translation_text': form['translation_text'],
})
return phrases
data = req.get('https://www.duolingo.com/api/1/dictionary_page', {
'lexeme_id': lexem_id,
'from_language_id': from_language_id,
}).json()
return {
'word': data['word'],
'lexem_id': data['lexeme_id'],
'image': data['lexeme_image'],
'tts': data['tts'],
'phrases': __get_phrases(data['alternative_forms']),
}
def get_translations(term, from_language_id='en'):
data = req.get('https://duolingo-lexicon-prod.duolingo.com/api/1/search', {
'query': term,
'exactness': 1,
'languageId': 'sw',
'uiLanguageId': from_language_id
}).json()
for result in data['results']:
if result['exactMatch'] is True: # we only allow exact matches
return result['lexemeId'], result['translations'][from_language_id]
return '', [] # no exact match is found
def get_everything(term, from_language_id='en'):
lexem_id, translations = get_translations(term, from_language_id)
try:
lexem_data = get_lexem_data(lexem_id)
except:
lexem_data = {}
info = {
'lexem_id': lexem_id,
'translations': translations,
**lexem_data,
}
return info
if __name__ == '__main__':
# here the dictionary gets loaded that was extracted previously
with open('duolingo-swahili-dictionary.json', 'r') as fp:
dictionary = json.load(fp) # type: dict
lexicon = {}
i = 0
n = len(dictionary)
for exercise, terms in dictionary.items():
print(f'{i / n * 100:.0f}%\t| Exercise: {exercise} - Terms: {len(terms)} terms\n\t', end='')
term_datas = []
for term in terms:
print(f'{term} • ', end='')
term_datas.append(get_everything(term))
lexicon[exercise] = term_datas
print()
i += 1
with open('duolingo-swahili-lexicon.json', 'w') as fp:
json.dump(lexicon, fp)
0% | Exercise: M/Mi Nouns - Terms: 30 terms
mche • mchezo • mchoro • mchuzi • mfereji • mfuko • miavuli • mikuki • mipira • misikiti • misitu • misumari • miti • mizizi • mji • mkasi • mkeka • mkutano • mlango • mmea • mnyororo • mpaka • mradi • mti • mto • mtumbwi • muziki • mzigo • wa • y •
2% | Exercise: Food - Terms: 34 terms
omba • bia • chai • chakula • chipsi • juisi • kahawa • karoti • kila • kuku • machungwa • maembe • maharage • maji • maparachichi • matunda • mayai • maziwa • mboga • mbuzi • mkate • ndizi • ng'ombe • nguruwe • nyama ya • nyanya • pilipili hoho • samaki • ugali • viazi • vinywaji • vitunguu • vitunguu saumu • wali •
3% | Exercise: Chores - Terms: 22 terms
fagia • washa • bafu • chumba • chupa • dirisha • faridi • fua • jamila • jiko • kikombe • meza • moto • ndoo • nguo • sabuni • safisha • sahani • sufuria • takataka • ufagio • vyombo •
5% | Exercise: Present Tense 1 - Terms: 11 terms
amka • cheza • penda • pika • soma • tembea • ana • lala • nina • tena • una
........
To see exactly how I imported the translations into Quizlet, please checkout the Jupyter notebook I created inside the repository: converter.ipynb. I basically separated the term and the translation by an @ character (this char is not present in the vocabulary) and then copy and pasted them into Quizlet.
All the sets for Swahili can be found here: https://quizlet.com/MelleDijkstra/folders/swahili-duolingo/sets. For most of the sets I added images to the terms to help you remember the words even more.
Happy learning! 😄